
可視化は目的ではない
「AIbot可視化」という言葉が広がってきた。GA4に映らないAIのアクセスを、サーバーログやCDN経由で捕捉し、画面に表示する。ここまでは、もう珍しい話ではなくなってきている。
しかし、可視化した先で何が起きているかというと、多くの場合「今月はAIボットが何件来た」「OpenAIが全体の何割を占めた」という量の報告で止まっている。
可視化はそれ自体が目的ではない。何を見て、何を判断するかがなければ、可視化は単なる集計作業で終わる。
この記事では、「AIbot可視化の次に来る問い」——何を見るべきか——を扱う。
量の可視化の限界
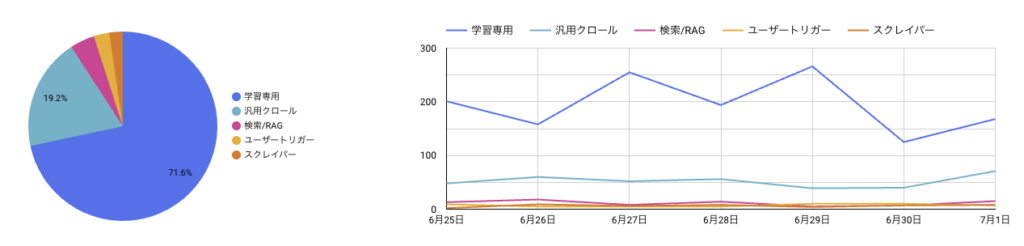
AIボットのアクセス数や運営元(operator)別の比率を見ても、意思決定に使える情報にはならない。理由は単純で、AIボットの大半は学習専用クローラーであり、これは「今」の意思決定に関係しないからだ。
学習専用クローラーが集めたデータは、将来のモデル学習に使われる。それがいつ、どのモデルの、どういう形の回答に反映されるかは分からない。
一方で、サイト運営者が知りたいのは「今、自分のコンテンツがAIにどう扱われているか」であることが多い。この2つは、まったく別の時間軸の話だ。
つまり、全ボットのアクセス数を集計してグラフにしても、そこには「今の意思決定に関係する信号」と「将来のための、今は使えないノイズ」が混在している。
しかも後者(学習専用クローラー)が量的に多数を占めることが多いため、量の可視化はノイズの可視化になりやすい。
実際、パス別の集計をそのまま出すと、robots.txtへのアクセスが最も多く、次いでsitemap.xml系が続くのが自明な結果になる。
これはボットが巡回を始める際に必ず最初に確認する経路であり、意思決定に使える情報ではない。
集計をそのまま眺めるだけでは、こうした自明な結果に埋もれて、本来見るべき信号が見えなくなる。
本当に見るべき軸:用途 × パス
意思決定に使える情報にするには、2つの軸を組み合わせる必要がある。
- 用途: このボットは何のために来ているのか(学習専用・汎用クロール・検索/RAG・ユーザートリガー)
- パス: どのページを見ているのか
この2つは、それぞれ単独で見ても意味が薄い。「OpenAIが62%」という比率だけでは何も分からないし、「/blogがよく見られている」というパスの人気度だけでも、それが学習専用クローラーの巡回結果なのか、検索/RAGボットが今まさに評価しているのかが区別できない。
用途 × パスのクロスを見て初めて、「検索/RAGのボットが、どのページを今の回答材料として評価しているか」が見えてくる。
これは、GA4のページビューがユーザー行動の意思決定材料になるのと同じ構造で、AI側の”今の評価”を追う手がかりになる。
botの用途は独自解釈ではなく、公式に定義されている
ここで重要なのは、この「用途別に見る」という発想が、こちら側の独自の切り方ではないという点だ。AI企業自身が、botの用途を公式に区別して案内している。
OpenAIの例で見ると、OpenAIは3種類のクローラーを運用しており、それぞれ設定を独立して制御できる。
OpenAIはウェブサイトやコンテンツがAIとどう関わるかを管理するために、OAI-SearchBotとGPTBotのrobots.txtタグを使っている。各設定は互いに独立しており、たとえばウェブマスターは検索結果に表示されるためOAI-SearchBotを許可しつつ、クロールされたコンテンツがOpenAIの生成AI基盤モデルの学習に使われないようGPTBotを拒否することができる。両方のボットを許可した場合、重複クロールを避けるために片方のクロール結果を両方の用途に使うことがある。
つまり:
- GPTBot → 学習専用。将来のモデル学習に使われる。
- OAI-SearchBot → 検索/RAG。ChatGPTの検索機能内で引用・表示するために使われ、モデル学習には使われない。
- ChatGPT-User → ユーザートリガー。人間がChatGPTに「このURLを読んで」と指示したときにだけ動く。
この3つは名前が似ているために混同されがちだが、OpenAI自身が用途を明確に分けて説明しており、robots.txtでの制御も個別に可能だ。
Anthropic、Perplexityなど他のAI企業も同様に、学習専用と検索/RAG・ユーザートリガー用のクローラーを分けて公開している。
AI企業側がここまで明確に用途を分けて運用しているのだから、可視化する側も同じ粒度、つまり用途ごとに見る必要があるはずだ。 運営元(どの会社のボットか)という軸だけを見て終わらせるのは、公式ドキュメントが示している分類の粒度をそこで止めてしまっているということになる。
もう一つの盲点:AIbotが読めるテキストがあるか
可視化の話とは別に、もう一つ見落とされがちな論点がある。それは、AIbotが訪れたとしても、そこに読み取れるテキストが存在するかという問題だ。
AIbotの多くは、ブラウザを操作してJavaScriptを実行するわけではない。ページのHTMLをそのまま取得し、そこに書かれている文章データを読み取る。
ところが、近年増えているリッチで動的なページ——JavaScriptが実行された後にコンテンツがDOMに挿入されるタイプの構造——では、AIbotが取得した時点でのHTMLに、肝心の本文テキストがまだ存在しないということが起こる。
これは可視化とは別の問題だが、根は同じところにある。「AIbotが何を見ているか」を追いかける前提として、「そのページにAIbotが読める形でコンテンツが存在しているか」が成立していなければならない。
可視化のダッシュボードにアクセスが記録されていても、そのアクセスで実際に本文が読み取れていたかどうかは、また別の話だ。
結論:可視化と設計は両輪
AIbot可視化を「量の記録」で終わらせないためには、次の2段階が必要になる。
- 用途 × パスで見る: 学習専用クローラーをノイズとして区別し、検索/RAG・ユーザートリガーのボットが今どのページを評価しているかを追う。この切り方は独自解釈ではなく、AI企業が公式に案内している用途分類に基づいている。
- AIbotが読める状態を保つ: 可視化で「見えた」としても、そのアクセス時にAIbotが本文を読み取れる構造になっているかを別途確認する。
可視化(見る)と設計(読める状態にする)は、どちらか一方だけでは機能しない両輪だ。次の問いは、「どうすればこの粒度で継続的に見られるか」になる。